我也支持向量机——ESL,PRML和MLAPP的知识反刍
如果感觉有民科风,请见谅,我本科是纯文科的外语专业,另外,这排版确实挺糟糕,权当是自己的学习笔记吧。
缘起
这件事情的起因,是师妹询问我支持向量机(Support Vector Machine, SVM)训练得到的模型参数,是否可以用来解释输入特征。当时我给出了一个比较随意的说法,大概意思是在线性核的条件下尚可,其余核的情况下并没有意义,特征分析还是找Logistic回归。
回过头来一想,这个讨论的基础实在诡异,讨论的内容也遍布想当然的预设和模棱两可的描述。所谓的“模型参数”是什么?是控制约束条件的拉格朗日乘子,支持向量,还是决策函数的参数?现在来看,我们当时自动对齐到了决策函数的讨论上,大抵是因为决策函数最容易与输入特征的线性组合联系起来,而我们又一不小心在线性参数模型的意识形态下看待了这个稀疏核方法吧。
尽管优化决策边界是支持向量机算法本质上做的事,支持向量及其对应的拉格朗日乘子(只考虑完全可分的情境)才是最终被收割的东西。对输入特征进行线性组合的决策函数,由于kernel trick的优势和需要,在做预测时也并不一定需要。
另一方面,与决策函数的输入维度一致的是特征映射空间的维度,原始特征一旦被映射到他维空间,其与决策函数的参数都未必能够维持一对一的关系,更难解释它们与参数间的关系了。所以,当时我所说的“线性核的条件下”指的应是不做特征映射的情况。这种情况下,决策函数是在对原始特征进行线性组合,就如同线性或者Logistic回归那样,参数权重当可以解释原始的特征。当然,这种情况下为何不用既直观、训练又快的后者呢?
如果要有个结论的话,用支持向量机的决策函数参数来解释原始输入特征这件事情,在特定情况下是可以做到的,但做这件事情就像拿板刷刷牙一样,刷牙我们还是会更喜欢使用牙刷。
以此为契机,我决定彻底收拾一下支持向量机的相关知识。也算是为明年面试找工作准备了。
我的收拾建立在对
- Pattern Recognition and Machine Learning (PRML),
- The Elements of Statistical Learning (ESL),
- Machine Learning A Probabilistic Perspective (MLAPP)
三本神书以及Stanford cs229 SVM笔记的参考之上。
支持向量机的两个视角
无论是PRML以及ESL从间隔最大化的视角切入,还是MLAPP从损失函数的视角切入,三本书都有所侧重地从两个视角构造支持向量机的优化问题,这两种视角殊途同归。
这其中,PRML以及ESL先从数据完全可分的情况讨论,之后才引入松弛变量讨论非完全可分的场景,这点与MLAPP的一步到位的叙述设计不同。
总体来说,MLAPP的篇幅较为紧凑(Murphy介绍SVM是有一些不得不讲的勉强感,详见章节14.5他给出的动机),MLAPP和PRML由于侧重概率模型,对于支持向量机在概率性质上的缺陷颇为关注,并且会拿SVM与概率性质较好的Relevance Vector Machine (RVM)对比。
相关论述章节:
- PRML: 7.1; Appendix E (回顾拉格朗日乘子在约束优化问题上的使用)
- ESL:4.5;12.1, 12.2, 12.3
- MLAPP: 14.5
1. 间隔最大化(几何)的视角
1.1 要做什么
我们来看图1.1。左右图的数据相同,我们关注左右图中的虚线,它们都是可以完美区分两类数据点的决策边界。左图列举了三个决策边界,右图列举了一个。

图1.1 寻找间隔最大的决策边界(图片来自Python Machine Learning by Sebastian Raschka)
图中,像这样对数据完美可分的决策边界实质上有无数条,而支持向量机的全部工作最终就是去收割右图中那唯一的一条。这个决策边界有何魅力值得SVM去追求呢?这里就要提到它唯一的特质:间隔最大。
我们关注这样的间隔。先看右图圈出的三个点,这三个点到虚线的距离相等。它们与其他数据点有什么不同?它们是所有点中最接近决策边界的,这些点任意一个到虚线的距离即是这里所说的间隔 (margin),更准确地说,是决策边界在训练数据集上的间隔。
以同样的方式考察左边图中与X轴垂直的那条虚线。与之最近的两个数据点(最下的红圈与最上的绿十字)到虚线的距离都非常小,均小于右图中三个点到虚线的距离。于是,我们说这条垂直决策边界的间隔小于右图中那条决策边界的间隔。
用相同的套路——计算到决策边界最近点到决策边界的距离,你会发现,左边图中所有虚线的间隔都是小于右图的。这就是在说右图中的决策边界的间隔是最大的。
直观地了解了SVM希望达成的目的,接下来就需要抽象出这个优化问题的数学描述了。具体的,我们需要刻画如下的对象和动作:
1.2 构造优化问题
1.2.0 前戏
我们约定,这里考虑完全可分的二类分类问题。设定正样本和负样本的分类标签分别为1和-1。
- 令线性决策函数为:y(x)=wT⋅x+b
- 在决策边界上的点满足:y(x)=0
- 训练数据集为:D={(x(1),y(1)),...,(x(N),y(N))},y∈{1,−1}
- 一些事实:
- 决策边界在平面内的单位法向量为:∣∣w∣∣w
- 分类正确的情况:y(n)(wT⋅x(n)+b)>0
1.2.1 距离

图1.2,计算数据点到决策边界(红线)的距离, 来自PRML 图4.1
图1.2为一个二维的例子,其中的虚线长度即为所要计算的距离,记为r,对于某个数据点(x(n),y(n)),可以将它到决策边界的距离表示如下:
r(n)=∣∣w∣∣±(wT⋅x(n)+b)
正号对应于正样本,负号对应于负样本,根据事实2以及我们约定的数据完全可分的条件,可将上式统一为:
r(n)=∣∣w∣∣y(n)(wT⋅x+b)(1)
补充: 图1.2中距离计算的详细步骤:
令数据点x在决策边界上的投影为 x⊥ ,对于距离r,由事实1我们可以得到:
x−x⊥=r∣∣w∣∣wx⊥=x−r∣∣w∣∣w
由于 x⊥ 在决策边界上,因此其决策函数预测值:wT⋅x⊥+b=0,
将x⊥代入决策函数后化简得到:
wT⋅(x−r∣∣w∣∣w)+b=0r∣∣w∣∣wT⋅w=wT⋅x+br=∣∣w∣∣wT⋅x+b
因为图中的数据是正样本,因此分子>0, 如果是负样本,则需要对分子取负号,最终得到
r=±∣∣w∣∣wT⋅x+b
注意,在这里我们的计算并没有依赖于图1.2中的几何形态,因此适用于任何维度空间的向量计算。
1.2.2 间隔
给定一个训练数据,间隔为其中数据点到决策边界的最短距离,可借助(1)式描述为:
nminr(n)=nmin∣∣w∣∣y(n)(wT⋅x(n)+b),n=1,2,...,N(2)
此式遍历数据集求出最小的距离,得到当前决策边界对应于训练数据的间隔。
1.2.3 最大化间隔
决策边界由参数对(w,b)决定,最大化间隔这个动作可借助间隔的表达式式(2)描述为:
w,bmax{nminr(n)}=w,bmax{nmin∣∣w∣∣y(n)(wT⋅x(n)+b)}
w,bmax{∣∣w∣∣1[nminy(n)(wT⋅x(n)+b)]}(3)
满足该式的参数对 (w∗,b∗) 即是这个优化问题的解。至此,我们已经形式化地表述了最大化间隔这个优化问题。
1.3 改造优化函数
陶醉地看了一会表达式,我们马上发现了问题。式子(3)虽然形式化了优化问题的目标,但以这样的形式硬杠求解得有多困难。特别的,它长得如此陌生,让我们难以和常规地优化技术联系起来。于是我们需要一个等价却更易于求解的形式,做这件事涉及到一些Trick。
Trick 1
先不管合不合理,我们去掉(3)式最小化的部分如何?我们强制:
nminy(n)(wT⋅x(n)+b)=1(4)
这样简单粗暴的一约束,(3)式便成为
w,bmax∣∣w∣∣1(5)
目标函数一下子清爽许多。
这样操作合不合理呢?注意,这个看似粗暴的约束并没有影响到我们的优化问题,即:
- 分类正确的情况:
y(n)(wT⋅x(n)+b)≥1>0
- 所有数据点到决策边界的距离:
假定(x(n∗),y(n∗)) 是任一到决策边界的最近点,未约束前我们有:
(wT⋅x(n∗)+b)=q>0
约束后,我们有:
y(n∗)(wT⋅x(n∗)+b)=1
这个约束动作等价于缩放决策函数的参数:
(w,b)∣∣w∣∣→(qw,qb)→∣∣qw∣∣
将缩放后的结果带入(1)式,我们发现分子分母同时缩放了1/q,因此相互抵消,所以缩放操作对所有数据点的几何距离都没有产生影响。
结论:这个粗暴操作粗中有细,是可行的。
-------- 注
ESL书中的式4.45和4.46表示形式与本文(3)式(即PRML与MLAPP的形式)的起始形式不同,但可以统一起来:
我们用(2)式表示最近点的距离r(n∗) ,交换等号两边、两边同乘以分母得到:
minny(n)(wT⋅x(n)+b)=r(n∗)∣∣w∣∣
ESL书中强设∣∣w∣∣=r(n∗)1 ,
带入上式可得:
minny(n)(wT⋅x(n)+b)=r(n∗)∣∣w∣∣=r(n∗)r(n∗)1=1
取最左和最右两项联立相等便回到了我们的(4)式上。
Trick 2
当然,约束(4)本身是一个对数据集合批处理的运算,这样一个运算作为约束条件也不太好操作,嗯,我是说,我们的拉格朗日乘子可是一对一地处理约束条件的。于是我们把这个batch操作个例化,(4)式被转述为以下约束条件的集合:
y(n)(wT⋅x(n)+b)≥1,n=1,...,N(6)
这里当且仅当(x(n),y(n)) 为到决策边界最近的点时取到等号,其余点的情况均严格大于1。由于决策边界在我们问题的情形下是必定存在的,所以等号是必定能够取到的,我们因此可以确定(4)和(6)式说的是同一件事情。
Trick 3
最后一个小Trick的动机是方便计算,我们把(5)式的二阶范数开平方(方便求导)、求倒数后从最大化转换为形如(7)式的最小化目标的形式。我们再把(6)式略变形后作为(8)式描述约束条件,这样便构成了改造后的不等式约束优化问题。
w,bmin2∣∣w∣∣2(7)
s.t. 1−y(n)(wT⋅x(n)+b)≤0,n=1,...,N(8)
瞥一眼原来的(3)式,改造后的问题已经是一个规整的带不等式约束的二次优化问题了。
1.4 构建拉格朗日函数求解优化问题
于是我们可以愉快地引入拉格朗日乘子来构造无约束优化问题:
L(w,b,α)=w,bmin{21wT⋅w+αmax{n=1∑Nα(n)[1−y(n)(wT⋅x(n)+b)]}}=w,bmin{αmax{21wT⋅w+n=1∑Nα(n)[1−y(n)(wT⋅x(n)+b)]}}(9)
其中,α=(α(1),...,α(N))≥0 的每一项是每个数据点对应约束条件的拉格朗日乘子,第一个min为我们原始的优化目标,后一个max则迫使最优解满足(8)中的约束条件。
三个变量的优化做起来很复杂,我们于是希望通过利用拉格朗日函数的对偶性,交换max(固定拉格朗日乘子求偏导数以试图获得w和b的表示)和min的求解顺序,把问题转化成由单一的拉格朗日乘子表示的形式(转化后的问题能确保最优解与原问题一致吗?)。
为了得到由式(7)、(8)所描述问题的对偶形式,令
∂w∂L(w,b)=w−n=1∑Nα(n)y(n)x(n)=0(10)
得到
w=n=1∑Nα(n)y(n)x(n)(11)
再令
∂b∂L(w,b)=−α(n)y(n)=0→0=α(n)y(n)(12)
把(11)、(12)代回(9)式并分别化解各项,
21wT⋅wn=1∑Nα(n)[1−y(n)(wT⋅x(n)+b)]=21(n=1∑Nα(n)y(n)x(n))T⋅(m=1∑Nα(m)y(m)x(m))=21n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(n)Tx(m)=n=1∑Nα(n)−n=1∑Nα(n)y(n)wT⋅xn−bn=1∑Nα(n)y(n)=n=1∑Nα(n)−n=1∑Nα(n)y(n)wT⋅xn=n=1∑Nα(n)−n=1∑Nα(n)y(n)[m=1∑Nα(m)y(m)x(m)T⋅xn]=n=1∑Nα(n)−n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(m)T⋅xn(13)(带入(10)式消元)(14)
将式(13)加上(14)最终得到原问题的对偶形式:
L(α)=αmax{n=1∑Nα(n)−21n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(n)T⋅x(m)}s.t. α(n)≥0,n=1,...,Nn=1∑Nα(n)y(n)=0(15)
有了这个目标函数,就可以用序列最小优化算法求得最优解:
α∗=[α∗(1),...,α∗(N)]
那么这个最优解是否是(9)式所描述问题的最优解呢?答案是肯定的,因为
1.我们的优化问题是凸优化问题;
2我们的优化问题满足KKT条件:
取得α∗时,我们有:
⎩⎪⎪⎪⎨⎪⎪⎪⎧∂w∗∂L=0,∂b∗∂L=0,∂α∗∂L=0α∗(n)≥0,n=1,...,N1−y(n)(w∗T⋅x(n)+b∗)≤0,n=1,...,Nα∗(n)[1−y(n)(w∗T⋅x(n)+b∗)]=0,n=1,...,N
前面三个条件是我们直接处理过的式子,最后一个条件为什么满足了呢? 结合(9)式,我们看到,这个条件的第二项(右项)是被最大化的项,
- 当1−y(n)(w∗T⋅x(n)+b∗)<0时,必须有α∗(n)=0才能使得两者乘积取得最大值0;
- 当1−y(n)(w∗T⋅x(n)+b∗)=0时,数据点是离决策边界最近的点,此时α∗(n)>0 (否则拉格朗日乘子全部为0),乘积仍然是零。
所以我们的第四个条件对于每一个数据点都成立。 正因为在这个问题上,KKT的所有条件都满足,所以,我们通过对偶问题求得的最优解,也即是原问题的最优解。
把最优解代回(11)并利用最近点使得决策方程值为1的条件求解参数,得到:
w∗b∗=n=1∑Nα∗(n)y(n)x(n)=y(n∗)−w∗T⋅x(n∗)
其中 (x(n∗),y(n∗))为距离决策边界最近的数据点,x(n∗)就是我们梦寐以求的支持向量了
注:
这里求b∗的做法和ESL中的相同,找任意一个支持向量数据点计算得到。PRML书中建议我们计算所有支持向量取平均以曾强鲁棒,
1.5 预测
利用最优参数得到预测函数:
y(x)=w∗T⋅x+b∗=n=1∑Nα∗(n)y(n)x(n)T⋅x+b∗(16)
在这个求和计算中非支持向量的拉格朗日乘子都为0,所以实际上我们只需要保存训练集合中的少部分支持向量及对应的拉格朗日参数α∗(n∗) 即可。
从决策函数上看,给定输入,这个模型对输入特征进行线性组合,加上偏置项后输出预测。
如果牵涉到特征映射,我们可以把上式写成下面的形式:
y(x)=w∗T⋅ϕ(x)+b∗=n=1∑Nα∗(n)y(n)ϕ(x(n))T⋅ϕ(x)+b∗(17)
回顾开篇时候讨论的“学到的决策函数的参数是否可以解释输入特征”,我们看到决策函数的输入空间对应的是特征映射后的特征空间,所以这种情况下,决策函数的参数就难以用来解释原空间的特征了。
进一步的,所谓的Kernel Trick,将式(17)中先作特征映射再计算向量的点乘的两步操作直接在kernel 函数中一步计算得到,这在某些情境下可以简化计算,也可以使得把原始特征映射到无穷维的空间中的计算变得可行。我们可以用kernel函数的形式来写出最终的函数预测形式:
y(x)=n=1∑Nα∗(n)y(n)k(x(n),x)+b∗(18)
可见,这种时候,决策函数的完全参数形态也未必需要保留。
至此,最大几何间隔的视角下完全可分情境下的SVM的流程已经回顾完毕。
1.6 中场休息:ESL和PRML的优化问题为什么殊途同归的可视化解读
在我们进入下一部分的讨论前,我需要交代一下愚蠢的我目前才搞清楚的细节,这些细节正因为过于基础,才会被三大神书直接略去不表,成为深坑留给我这种修为的读者钻。
来看图1.3这张我耗时绘制成的巨作,这是将一个类似图1.1的例子(数据并不一致)还原在了三维的空间中。
一些事实:
-
在三维空间中,图1.3的半透明平面(函数平面)即是所有(x1,x2,w1x1+w2x2+b)点所在的平面(因为第三维度是前两个维度的线性组合,所以函数在一个平面上。你可以试着想象Logistic函数那个S形的半透明函数面)。
-
决策边界在三维空间中,是函数平面与z=0(用z表示竖直轴)平面的交线,而灰色的平面即是平面z=0,也就是图1.1的那个平面。
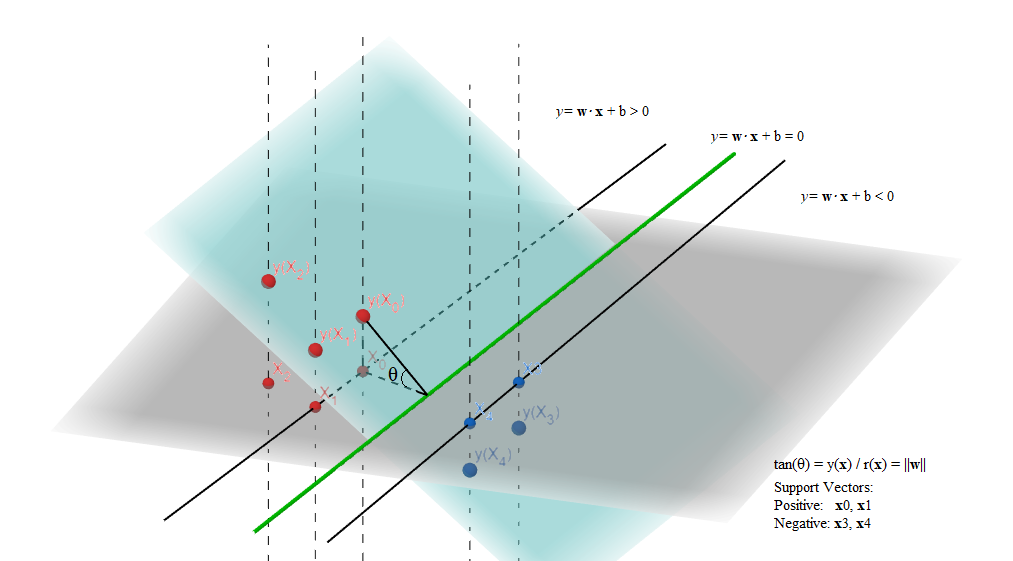
图1.3 决策函数平面与决策边界的三维重建图,用geogebar的3D Graphing绘制
-
在图1.3中,红色点和蓝色点为正、负样本,取得的决策函数值分别大于、小于零,位于函数平面被分割后的两截。
-
越远离决策边界的点由函数平面投影到z=0平面的高度越高。
图1.3画出了四个支持向量,看其中一个x(0) (请自动和图中点的表示对其),我们有其到决策边界的距离r(0)(即为间隔),其决策函数值y(x(0)),于是我们可以表示图中夹角θ的正切tan(θ)=r(0)y(x(0))。
还记得我们的(1)式说r(n)=∣∣w∣∣wT⋅x(n)+b=∣∣w∣∣y(x)吗?把(1)式套用在这里,我们得到:
tan(θ)=r(0)y(x(0))=y(x(0))y(x(0))∣∣w∣∣=∣∣w∣∣
于是ESL的强令操作就可以反映在图1.3中了。根据ESL在P132的4.47式下方的文字,在这里我们强令 ∣∣w∣∣=r(0)1=tan(θ),我们看到这实质上就是在强令图1.3中直角三角形的角θ的对边长度为1,而不约而同的,我们的(4)式体现在图中,也正是在强制这条边的长度为1,于是两本神书的操作殊途同归。
而强令θ的对边长度为1,也可以看作是将图1.3中半透明的函数平面旋转到特定的角度。这样的旋转,既不影响决策函数的预测——对于决策我们只关心决策函数预测值的符号(即只要确保正负样本位于函数平面被切割的不同侧),也不改变z=0平面上的点到决策边界的距离,因此是可行的。
1.6 非完全可分情况
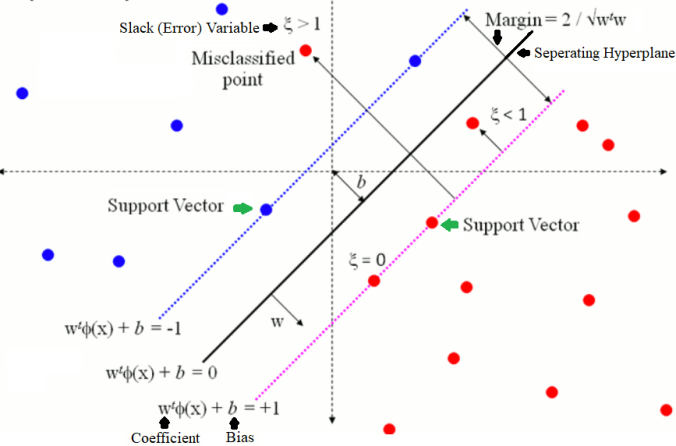
图1.4,非完全可分的情境,有一个红点分错,另一个红点虽然分对但是在决策边界和支持向量之间,图片来自网络
在图1.4中,值得我们注意的有两类情况:
- 类别错误的点
- 那些虽然类别正确,但是比较勉强、位于决策边界和支持向量之间的点。
回顾图1.3,支持向量到函数平面的高度(值为1)最小,而这个高度也是分类决策的阙值:正确分类的点的高度必须在其所对应的半平面内高于决策向量的高度(即,其高度≥1)。对于错分点来说,其高度是小于0的。而位于间隔内的点的高度则都在[0,1)这个区间中。
直观上看,要让间隔内的点甚至错分点能够被判断为正确的分类结果,我们能做的事情就是拉低1这个阙值。于是,对于每个数据点,我们引入所谓的松弛(松弛了投射高度为1这个硬门槛)变量以控制它们的分类结果:
y(n)(wT⋅x(n)+b)≥1−ξ(n)ξ(n)≥0,n=1,...,N(19)
这就是所谓的软间隔。我们看到,之前在硬间隔能被正确划分的点并不会受到影响,而随着ξ将门槛拉低,在间隔内的点的高度将有可能大于这个新的门槛,因而被当作分类正确的点。更激进的情况下,当ξ>1时,1−ξ<0,意味着原本该被判断为分类错误的点也有机会被当作正确划分的点看待。
1.6.2 修改目标函数
一旦引入松弛机制,我们原本严格的判断将会受到影响,而我们希望这种影响尽可能小,这样才不会太激进地让过多错误情况被接受。因此,我们把松弛变量作为一个需要最小化的损失项加入到原来的目标函数(7)式中得到新的目标函数:
w,bmin2∣∣w∣∣2+Cn=1∑Nξ(n)
这里C为一个超参数,用于控制惩罚的强度,当C趋向无穷大时,只允许正确分类且数据点不能位于间隔之内,意味着恢复为原始的硬间隔。反之,一个较小的C值允许一些决策不够好甚至错误的情况存在,使得模型的容错性更高。
于是我们将完整的优化问题表述如下:
w,bmin2∣∣w∣∣2+Cn=1∑Nξ(n)(20)
s.t. 1−ξ(n)−y(n)(wT⋅x(n)+b)≤0−ξ(n)≤0,(21)
1.6.3构建拉格朗日函数求解优化问题
L(w,b,α,μ,ξ)=w,ξ,bmin{∣∣w∣∣2/2+Cn=1∑Nξ(n)+α,μmax{n=1∑Nα(n)[1−ξ(n)−y(n)(wT⋅x(n)+b)]+n=1∑Nμ(n)(−ξ(n))}}(22)
其中,{α(n)≥0},{μ(N)≥0}均为拉格朗日乘子。
为将原问题转化为对偶问题,我们对参数求偏导并令偏导数为0:
∂w∂L=0∂b∂L=0∂ξ(n)∂L=0⇒w=n=1∑Nα(n)y(n)x(n)⇒n=1∑Nα(n)y(n)=0⇒μ(n)=C−α(n)(23)(24)(25)
将参数w,b,μ(n),ξ(n) 用以上的式子消去后,得到原方程的对偶形式:
L(α)=αmax{=αmax{21n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(n)T⋅x(m)+Cn=1∑Nξ(n)+n=1∑Nα(n)−n=1∑Nα(n)ξ(n)−n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(n)T⋅x(m)−n=1∑Nα(n)y(n)b−Cn=1∑Nξ(n)+n=1∑Nα(n)ξ(n)}n=1∑Nα(n)−21n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(n)T⋅x(m)}(26)
由式(24)和(25)得到α(n)的约束条件为:
0≤α(n)≤C,n=1,...,Nn=1∑Ny(n)α(n)=0
于是原问题的对偶问题为:
max{n=1∑Nα(n)−21n=1∑Nm=1∑Nα(n)α(m)y(n)y(m)x(n)T⋅x(m)}s.t. −α(n)≤0,α≤C,n=1,...,Nn=1∑Ny(n)α(n)=0(27)
这是一个带不等式和等式约束的二次优化问题,可以同样使用的SMO算法求得最优解。
分析KKT条件:
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂w∗∂L=0,∂b∗∂L=0,∂α∗∂L=0,∂ξ∗∂L=0,∂μ∗∂L=0α∗(n)≥0,n=1,...,N1−ξ∗(n)−y(n)(w∗T⋅x(n)+b∗)≤0,n=1,...,Nα∗(n)(1−ξ∗(n)−y(n)(w∗T⋅x(n)+b∗))=0,n=1,...,Nμ∗(n)≥0,n=1,...,N−ξ∗(n)≤0μ∗(n)ξ∗(n)=0
注意,α(n)的最优解可以通过线性变换转换为ξ(n)的最优解;当−ξ∗(n)<0时,必须有μ∗(n)=0才能使得目标函数最大化。综上,KKT所有条件均得到满足,所以对偶问题的最优解也是原问题的最优解。
1.6.4 预测
预测函数同式(16)或(18)(kernel trick的话)。所有α∗(n)>0 的数据点成为支持向量,它们满足y(n)(w∗T⋅x(n)+b∗)=1−ξ∗(n)。
根据式子(25),当α∗(n)<C时,我们有μ∗(n)>0,因此必然有ξ∗(n)=0说明这些支持向量在间隔边缘(即他们是原来硬间隔下的支持向量)。而当α∗(n)=C时,有μ∗(n)=0,意味着ξ∗(n)>0。这部分支持向量为错分类点(ξ∗(n)>1),或者是间隔内部的点(0<ξ∗(n)≤1)。
参数w∗的计算公式与硬间隔条件下的相同,做出贡献的是所有类别的支持向量:
w∗=n=1∑Nα∗(n)y(n)x(n)
对于参数b∗的计算,我们可以利用任意一个硬间隔边界上的支持向量(x(n∗),y(n∗))得到:
b∗=y(n∗)−w∗T⋅x(n∗)=y(n∗)−n=1∑Nα∗(n)y(n)x(n)T⋅x(n∗)=y(n∗)−n=1∑Nα∗(n)y(n)k(x(n),x(n∗))
注意最后这里写成了kernel的形式。同样的,按照PRML的建议,可以对支持向量求平均以增强鲁棒,只是这个平均是对所有在硬间隔边界上的支持向量进行操作。
2. 损失函数的视角
2.1 分类
相对几何视角,损失函数设计的动机让我这种缺乏背景的民科比较难以猜测,也许只能硬这么理解。引入铰链损失(Hinge Loss):
Lhinge=max(0,1−ξ−y⋅(wT⋅x+b))=[1−ξ−y⋅(wT⋅x+b)]+(28)
注意我们引入了疏松变量ξ以应付线性不可分的情况。这个决策函数和我们在几何视角下分类正确的约束条件——(19)式——本质上是一致的。当预测结果正确,并且预测值的绝对值大于1−ξ时,说明分类器对正确分类的把握较大,于是对这些训练数据点的判断不产生损失。而当分类错误、或者分类正确但把握不大(即预测值的绝对值小于1−ξ)都将产生非零的损失。这和几何视角下图1.3呈现的数据点到函数平面的高度是否大于软间隔的思想也是一致的。
最小化损失函数,并且用l2正则模型参数项,我们得到待优化的目标函数:
w,bminn=1∑N[1−ξ(n)−y⋅(wT⋅x(n)+b)]++λ∣∣w∣∣2(29)
其中λ=2C1,这个问题在形式上与几何视角下最大化间隔的目标函数(20)(21)等价,用同样的套路解决即可。
2.2 回归
线性回归中,我们有加入l2正则项的目标函数:
21n=1∑N[y(n)−y^(n)]2+2λ∣∣w∣∣2
其中y(n),y^(n)=wT⋅x(n)+b分别为目标值和模型预测值。
所谓的支持向量回归(Support Vector Regresso, SVR )将这个目标函数的第一项——平方损失项——替换为所谓的ϵ-insensitive损失函数:
Lϵ={0,∣y^−y∣−ϵ,if∣y^−y∣<ϵotherwise
即当预测值和目标值的差距超过了ϵ这个阙值,该数据就会贡献损失。
我们同样可以加入疏松变量,只是这个时候需要考虑两类情况,一类是预测值高于目标值,另一类是预测值低于目标值:
y^(n)≥y(n)−ϵ−ξl(n)y^(n)≤y(n)+ϵ+ξu(n)(30)
其中ξu(n),ξl(n)≥0分别用于疏松目标值+ϵ和−ϵ上下的阙值。对于一个训练数据点,在硬阙值下预测值不能小于y(n)−ϵ,也不能大于阙值y(n)+ϵ。经过疏松后,一些在这些阙值之外的不合法点也可以被认为是预测正确的点。
借助图1.3可以想象,被拟合函数的图像应该具有起伏不平的外貌。
结合约束和损失函数,SVR的优化目标可以描述为:
w,b,ξu,ξlmin{Cn=1∑N(ξl(n)+ξu(n))+21∣∣w∣∣2}s.t. −(wT⋅x(n)+b−y(n)+ϵ+ξl(n))≤0wT⋅x(n)+b−y(n)−ϵ−ξu(n)≤0−ξu(n)≤0,n=1,...,N−ξl(n)≤0,n=1,...,N(31)
写成无约束的拉格朗日函数形式:
L(w,b,ξu,ξl,αu,αl,μu,μl)=w,b,ξu,ξlmin{αu,αl,μu,μlmax{Cn=1∑N(ξl(n)+ξu(n))+21∣∣w∣∣2+n=1∑N−(μu(n)ξu(n)+μl(n)ξl(n))+n=1∑N−αl(n)(wT⋅x(n)+b−y(n)+ϵ+ξl(n))+n=1∑Nαu(n)(wT⋅x(n)+b−y(n)−ϵ−ξu(n))}}(32)
其中, αu(n),αl(n),μu(n),αl(n)≥0 为对应于每个数据点的上下疏松变量的拉格朗日乘子。
为将(32)式转化成对偶形式:
∂w∂L=0∂b∂L=0∂ξu(n)∂L=0∂ξl(n)∂L=0⇒w=n=1∑N(αu(n)−αl(n))x(n)⇒n=1∑N(αl(n)−αu(n))=0⇒αu(n)+μu(n)=C⇒αl(n)+μl(n)=C(33)(34)(35)(36)
用以上式子对式(32)进行消元,得到原始方程的对偶形式:
L^(αl,αu)=αl,αumax{−21n=1∑Nm=1∑N(αl(n)−αu(n))(αl(m)−αu(m))x(n)T⋅x(m)−ϵn=1∑N(αl(n)+αu(n))+n=1∑N(αl(n)−αu(n))y(n)}s.t. 0≤αu(n)≤C,0≤αl(n)≤Cn=1∑N(αl(n)−αu(n))=0(37)(38)(39)
这是一个带不等式约束的二次优化问题,用Solver求得最优解:αu∗,αu∗
分析KKT条件:
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂w∗∂L=0,∂b∗∂L=0,∂αu∗∂L=0,∂ξu∗∂L=0,∂μu∗∂L=0,∂αl∗∂L=0,∂ξl∗∂L=0,∂μl∗∂L=0−ξu∗(n),−ξl∗(n)≤0,n=1,...,Nμu∗(n),μl∗(n)≥0,n=1,...,Nμu∗(n)(−ξu∗(n))=μl∗(n)(−ξl∗(n))=0,n=1,...,Nαu∗(n),αl∗(n)≥0,n=1,...,N−(w∗T⋅x(n)+b∗−y(n)+ϵ+ξl∗(n))≤0w∗T⋅x(n)+b∗−y(n)−ϵ−ξu∗(n)≤0−αl∗(n)(w∗T⋅x(n)+b∗−y(n)+ϵ+ξl∗(n))=0,n=1,...,Nαu∗(n)(w∗T⋅x(n)+b∗−y(n)−ϵ−ξu∗(n))=0,n=1,...,N
为实现对偶函数的最大化,对于αl∗(n)>0的训练数据点,必须有y^(n)−y(n)+ϵ+ξl∗(n)=0,也就是说预测值存在两种可能的情况:1)当疏松变量ξl∗(n)=0时,预测值正好落在−ϵ边界上,即y^(n)=y(n)−ϵ;2)当ξl∗(n)>0时,预测值在−ϵ阙值之下,受益于疏松变量拉低了下边界,该预测值才被视作预测正确。以同样的方式可以解读αu(n)>0对于上边界预测的影响。
再者,一个数据对应的αu(n)和αl(n)不可能同时取非零值。对于一个预测值y^(n),它或者大于、或者小于目标值y(n),因此其对应的αu(n),αl(n)中至多有一个可以为非零,因为非零意味着该预测值在上下硬边界上或者硬边界之外,而因为ϵ>0,上下边界间距为2ϵ,这样一来,一个预测值不可能既在y(n)−ϵ的下边界上,又在y(n)+ϵ的上边界上(或者比上边界还要高的位置)。
对于第四个KKT条件,位于ϵ边界上的数据点有ξu∗(n)=0或者ξl∗(n)=0,条件满足;而当−ξu∗(n)<0或者−ξl∗(n)<0,μl∗(n),μu∗(n)只有取0值才能使得整个式子取得最大值,这个时候,条件式子仍然等于零,因此条件满足。
所以,KKT的所有条件均满足,对偶问题的最优解也是原问题的最优解。
由式(33)可知所有这些αu,l(n)非零的数据点会成为“支持向量”,为函数拟合贡献力量。这些数据点对应的函数预测值要么位于上下ϵ-边界上,要么在这个边界区域之外。而所有αu∗(n)=αl∗(n)=0的数据点的预测值则都在ϵ-区域之内可以被严格地正确预测。
表示参数
我们可以将参数表示如下:
w∗=n=1∑N(αu(n)−αl(n))x(n)b∗=y(n∗)−ϵ−w∗T⋅x(n∗)(40)(41)
其中,类似分类情况,部分的数据点——支持向量——贡献决策函数的预测。对于参数b∗我们可以任意取一个满足如下条件的支持向量(下标{u,l}表示或)
{α{u,l}∗>0μ{u,l}∗>0⇒{α{u,l}∗>0α{u,l}∗<C 由式(35)或(36)
根据KKT条件第四条,此时必须有ξ{u,l}∗(n)=0。因此,满足这些条件的支持向量,它们的预测值位于ϵ-区间的边界上。我们利用其中任意一个,将它带入KKT条件最后两条中适用的那一条便得到:wT⋅x(n)+b−y(n)−ϵ=0从而求得b∗
当然,根据PRML的建议,为所有满足条件的支持向量计算b∗值并求平均会更robust。
这样我们的最终的预测函数为:
y(x)=n=1∑N(αu∗(n)−αl∗(n))x(n)T⋅x(n)+b∗
可以写成kernel的形式:
y(x)=n=1∑N(αu∗(n)−αl∗(n))k(x(n),x(n))+b∗
3. 算法分析
- 需要学习的参数个数:
- 带疏松变量的二类分类支持向量机对偶形式:N
- 带疏松变量的回归支持向量机对偶形式: 2N
- 训练时间复杂度:
- 如果用通用的二次规划Solver,O(n3)
- 如果用SMO算法,O(n2)。PRML指出,在实践中根据具体任务的不同,平均时间开销与数据量的比例在N到N2之间。当使用线性核函数的时候,训练时间复杂度可以降低到O(N)
- 稳定性:
算法对于异常值会很敏感,因为异常值有可能成为支持向量,干扰模型预测。
总结
呼,总算可以暂时告一个段落了。总的来说,SVM有许多trick,在图1.3中可以反映很多,在绘制这张图的时候,有很多之前粗粒度阅读所忽视的细节问题都被暴露出来,并且自己通过思考找到了答案,可谓收获很大。
另外,之所以硬杠三个凸优化的对偶形式转换和KKT条件分析,是想熟练一下凸优化的操作套路,可谓经验收获很大。
虽然SVM已经算不得最流行的机器学习算法,但是学习它仍然可以锻炼有价值的思考方式,特别是那种将直观的思想(最大化间隔)形式化求解的思考过程。这种技能说不定未来哪个时候一不当心就可以派上用场。
SVM可谓线性模型的一个巅峰。抛去线性方程的形式,它就是一种稀疏化了的核方法,支持向量就是从稀疏操作中幸存下来的那些对预测最有用的训练数据点。
最后,对比三本神书SVM的介绍,个人感觉PRML的阅读下来更顺畅一些。MLAPP则可以看作是对PRML的继承和补充。